Motivation
I had spent the better part of a year and a half thinking about and researching what I would have want a next-gen AI framework to be. This framework was intended to live within the engine layer and provide a generalized architecture for writing and executing any kind of game AI. I think the best description of the intentions was that I was trying to build a “genre and game agnostic” AI system. My primary concerns with the framework’s design were ones of production. I don’t believe AI can continue to exist only in code and we need to embrace more data driven approaches in terms of authoring AI. In any case, this viewpoint is not shared by the vast majority of my peers which often makes discussions about this topic quite difficult but as part of this generalized framework research, I did a fair amount of work on behavior trees (BT). I went through numerous iterations on the core BT architecture. As part of this work, I came to some conclusion for overall decision making and behavior authoring. For the most part, this work was abandoned and I’ve now resigned myself to the fact that I will probably not get a chance to move forward with it. I feel the information is still useful and so I would like to share my ideas and conclusions in hope that it might trigger a discussion or inspire someone to do something awesome and crazy. This information sharing will be split into two articles, the first discussion about my final BT architecture and and the second will delve into my conclusion and why I feel that way.
NOTE: It is also extremely important to make it clear that that what I am about to discuss is not new techniques or ideas but rather an attempt to formalize some concepts and architectures of behavior trees. This information is necessary for the follow up article.
Introduction
I don’t really want to rehash old information, so I will assume that anyone reading this is familiar with the basic concepts of the behavior trees. If not I would direct you to the following resources:
- AIGameDev (http://www.altdevblogaday.com/2011/02/24/introduction-to-behavior-trees/)
- Bjoern Knafla’s write up on AltDevBlog: (http://www.altdevblogaday.com/2011/02/24/introduction-to-behavior-trees/)
- “Artificial Intelligence for games“– I. Millington / J. Funge (though this is just an amalgamation of the info available online)
So now that that’s out of the way then let’s move forward. The first thing you might notice when discussing BTs is that a lot of people will refer to them as reactive planners. What they actually mean by reactive planner is simply a “BIG IF STATEMENT”. The reactive part means that each time you evaluate the tree, the result could change based on the environment i.e. it will react. The planning part simply implies that for some given set of values, the conditions for the tree, it will select some authored plan of actions to execute. I’m sure a lot of programmers (and potentially academics) are probably raging at my gross over simplification of BT so let me give a basic example:

Traditionally, behavior tree evaluation starts at the root, and proceeds, depth first, down the tree until it reaches a successful node. If an environmental change occurs that the affects the tree, it will be detected on the next evaluation and the behavior changed accordingly. This implies that you need to be careful when authoring the tree to ensure higher priority behaviors are placed before lower priority behaviors so that we get the proper “reactivity”.
One thing that initially bothered me when looking at various behavior tree implementations was that whereas I saw then as tool to author actual behaviors, a lot of programmers saw BTs as a way to describe the transitions between behaviors. What I mean by is that the granularity of actions in their trees was quite low. You would see leaf nodes such as “FightFromCover”, “GoToCover” or even worse stuff like “RangedCombat” and “InvestigateSuspiciousNoises”. That’s not to say its always the case, I have seen examples of BT with a much higher granularity in their nodes such as “moveto”, “shoot”, “reload”, “enter cover”, etc… This, at least for me, seemed like a more attractive alternative as it allows designers to actually prototype and author new behaviors without depending on a programmer to build the behavior. I envisioned a workflow when game designers could to a large degree script with BTs. The reality is that a lot of newer designers in the industry are not able to script using code and since I don’t want to artificially lock them out, I wanted to provide a toolset for them to be able to have some degree of autonomy with their prototyping and designs.
There is one downside to increasing the granularity: massive growth of the tree size and this can have a pretty bad effect of the performance profile of a tree evaluation especially when in the lowest priority behaviors. Given the simple tree below, to reach our currently running behavior, we needed to evaluate numerous nodes earlier in the graph. For each subsequent update of the behavior we still need to traverse the entire tree, checking whether anything has changed and whether we need to switch behavior. With massive trees, the cost of this traversal can quickly add up. This cost is especially depending on the cost of your condition checks as they will make up the bulk of the operations performed. I hope the irony that the most expensive BT update occurs when the agent is doing nothing, is not lost on you.
RANT: To be frank, I find a lot of performance discussions regarding BT’s to be misleading. I would love to be in a situation where the most expensive thing in my AI update was the actual tree traversal and not the work being done by the nodes. The condition nodes alone, will almost certainly incur cache misses when querying your knowledge structure (be it a blackboard or whatever) as will any calls into other game systems. Barring some sort of idiotic implementation, I think that your time optimizing a BT is better spent in minimizing the cost of the work being done by the nodes and not the traversal of said nodes.

Naively, my first thought to get around this problem was that I didn’t need to re-evaluate the entire tree each time. I could simply just resume evaluation at my last point. This is similar toward AIGameDev’s “Event driven behavior trees” but there are some problems with this approach, some that are not covered in the AIGameDev (http://www.youtube.com/watch?v=n4aREFb3SsU) materials. The main problem is that you lose the reactivity of the tree, what I mean by that is that you will only ever react to new events only once the tree finishes an evaluation i.e. a behavior fully completes. It’s also unclear what happens in the case of parallel nodes, as we could at any given point be running N behaviors in parallel across multiple branches of the tree.
Stored State Behavior Trees
After some thought, I decided that there was no way around repeating the evaluation from the root each frame without losing basic functionality. Instead, what I decided to do to limit the amount of work done, by storing the state of each node across subsequent evaluations. I would store the state of each node as it was calculated, then on subsequent evaluations, I would skip all the nodes that had previously completed (succeeded or failed). The stored state of the BT nodes would only be reset once the tree fully completes the evaluation. For clarity’s sake I’m gonna refer to these technique as a Stored State BT (SSBT).
At this point, I’m sure a lot of you are asking yourselves how is this any different from “Event Driven BTs”? Well, let work through an example and the differences should become clear. Given the following tree allowing our agent to investigate a sound:

In the traditional BT model, we will evaluate the entire tree each AI update which means we will detect the noise as soon as it happens. Great so what happens with my approach? Well everything works great on the first AI update. We correctly select the smoking idle behavior and we store each node’s state. The tree state looks as follows:
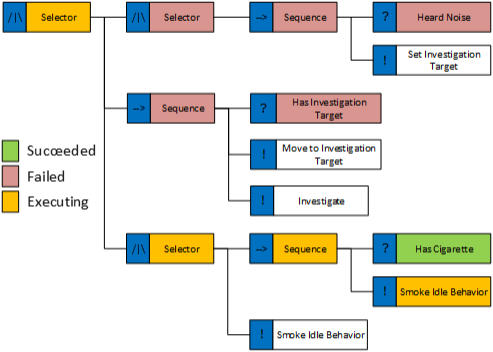
On the second update, nothing has changed, so we evaluate the tree skipping all nodes that have completed (i.e. succeeded or failed) and we re-enter the smoking behavior and update it. So far so good. On the third update, a noise is detected, but since our evaluation skips completed nodes, we never enter the first sub-branch until the smoke behavior completes and so we will not react to the sound. This is obviously broken.
Before I discuss a solution I also want to point out a big problem with standard BTs. Let’s take a look at the middle branch (the actual investigation behavior). Each time we evaluate the tree, we will detect that we have an investigation target and run the “move to investigation target” behavior and it is when that behavior completes that things start becoming nasty. Not only are we running the “has investigation target” check each subsequent update but now we also need to verify that we are in fact at the correct required position to be able to progress past the “move to investigation target” node in the tree. Now imagine that the “investigate” behavior actually moves the character. Next time you update the tree, the move to investigation target kicks back in and tried to the adjust the position of the character back to the required point. Congratulations! You are now officially an AI programmer as you have encountered the dreaded behavior oscillation problem. There are a bunch of ways to fix this but all are, in my opinion, workarounds and hacks due to sub-optimal decision making. One of my biggest problems with traditional BT is that most people simple treat them as a glorified decision tree, anyways I’m getting side-tracked but this problem is a very common one, and one that’s not really mentioned in a lot of the BT literature 😉
Back to my broken BT model! A naïve approach to fixing the problem that we don’t enter the first branch (the first selector node) could be to put a “repeat” decorator on it. A “repeat” decorator will cause its decorated node to be reset and re-evaluated each AI update. This decorator is entirely useless in the traditional BT approach but does some value with the SSBT model. Does it fix our problem? Well, sort of, it does fix it but only in that specific case. Consider the following modification to the tree:

The repeat decorator was moved to after the first selector node and a sequence was added before it. Granted this example is bit contrived but it does highlight a very real problem. As a result of this setup, after the first evaluation the first sequence node’s status is set to “failed” and on the subsequent evaluation the repeat node will not be reached so we are back to the original problem. The solution I found this problem was actually quite simple. I created a new decorator called a “Monitor”. This decorator had an interesting behavior in that when encountering a Monitor decorator, we would evaluate its child node and store the result of that evaluation (just as before) but the monitor would also register itself to a “monitored nodes list”. Due to the depth first nature of the tree, we would only register monitor nodes with a higher priority that our current branch in the tree. On the AI update after we registered the monitor nodes, we would evaluate all registered monitor nodes in the tree before the tree evaluation step. This simple mechanism allows us to maintain the reactivity of the tree but also prevents us from doing a lot of redundant work. The monitor concept is show in the figure below.

As with any technique, there is a bit of catch, well not a catch but rather that you need to change your way of thinking about the behavior tree. The monitor node concept is powerful but there are some more details concerning the monitor nodes and the SSBT model that need mentioning. Remember I mentioned that we have the concept of resetting the tree? This is something similar to the “OnTerminate” call that Alex shows in his BT video. We reset nodes primarily when the tree has been fully evaluated i.e. all active leaf nodes complete, in that case we call reset on the root node which traverse the tree and reset of all child node that require resetting.
There is also the issue of the resulting state of the monitor nodes. Since we evaluate the list of monitored nodes before we evaluate the tree (essentially evaluating them as standalone trees) what do we do with their return state? Well, this is where the reset comes in. If a given monitored node succeeds, it will return an interrupt result which will cause us to reset the tree and restart the evaluation. This allows us to maintain the reactivity of the tree but also gives us the added benefit of clearing the entire state of the tree, more on that in a bit. Since monitor nodes can reset the tree and will always be evaluated, I would strongly suggest that no actual behavior be placed within them. I used the nodes to perform knowledge and world state queries to see if anything had occurred that I needed to react to. I also tended to use generalized cases for the monitor nodes I had i.e. did I hear a new sound of some class, did I see something I need to react to, etc… In my opinion, the monitor decorator tends to give the AI programmer/designer a bit more control over the performance characteristics of the tree than before.
It’s also worth getting into a bit more detail with regards to the reset mechanism of the BT. Resetting a node allows us to actually perform some state clean up operations before re-evaluating the tree. I found this concept extremely powerful in that it allowed me to have synchronicity in actions for the nodes. What I mean by that is that, for example, certain action nodes would change the agent’s knowledge i.e. a talk node would set a “isSpeaking” flag, or a movement node would set a “isMoving” flag and so on. This meant that during the reset of the tree, each node could clean up after themselves in a sensible manner i.e. clearing any flags it had set or sending termination commands to the animation layer.
A good example of this would be if we were interrupted during a full body interaction with the environment. We can, during the reset of the tree, send an interrupt command to animation layer and have it sensible blend out of the act. This would normal have been achieved with checks at a higher level in the tree i.e. if (in animation && animation can be interrupted ) then interrupt. With the reset concept we get two benefits for free:
- We don’t have to worry about interrupting behaviors since they can clean up after themselves removing the need for additional checking earlier in the tree. This really helps in reducing issues arising from bad state due to tree interruption
- All clean-up is localized to the nodes, each node knows exactly how to clean up after itself. Meaning that you can really have modular nodes that are plug and play within the tree, without having to worry about their potential effects in the context of multiple traversals.
Honestly, I think the reset concepts was one of the nicest things about this BT and the resulting implementation code ended up being really simple and elegant.
Lastly, the SSBT model has one additional benefit, it actually solves the oscillation problem we mentioned earlier. Since we store the state for a node, once the “move to investigation target” behavior completes, we never have to run it again. Since we track the state, we know that we’ve completed it and can simply let the “investigate” behavior take over. I found this to be quite an elegant solution over the alternative.
So now we find ourselves back to the same functional behavior as with the original BT model. In my opinion, I feel that the SSBT model actually has some functional and authoring improvements over the traditional model but hey, I’m biased! As I mentioned earlier, I believe that any performance problems with BTs are a result of the work done by individual nodes rather than due to the traversal of the actual tree structure. I also feel that the stored state evaluation approach really goes a long way to limit the amount of work needed to be performed during each tree evaluation.
Note: Maybe some of the keen readers have noticed what the SSBT model has actually resulted in? It wasn’t immediately obvious to me either. When I finally realized it, I was shocked. Don’t get me wrong, it works exactly as intended and I really liked the elegance of the solution and implementation but it led me down a rabbit hole that change my entire perspective of the topic.
Synchronized Behavior Trees
So let’s actually get to the synchronized part of the post title. One thing I didn’t mention was that, I only starting playing with the evaluation model after I had already done some of the work discussed in this part, it just made more sense for the writeup to discuss it in this order.
When I started thinking about the AI framework, my target platforms were both current and next gen. As such memory savings in the order of a few MBs were still really important. Now behavior trees are probably not the most memory intensive things you’ll encounter but I also had the idea of having all of crowd run in the new AI framework. In fact, I wanted to not make any distinction between crowd and NPCs from the AI’s perspective. As such, I was considering having several thousand behavior trees instantiated simultaneously. Let’s say I wanted 5000 characters, and each tree took 3kb, that’s around 15MB of data, there is no way that memory budget would ever be approved on 360/ps3 platform. So decided to share the same tree across all agents. This approach has already been touched upon with Alex’s data oriented trees.
My approach was pretty simple, each BT node would have a method called “GetMemoryRequirements” that would return the memory size needed to store its require instance state data, as well as all the memory needed for the node instance data of its children. I would then, for a given tree, calculate the required space needed to store all of the node’s instance data for an agent by calling “GetMemoryRequirements” on the root. I also made the choice then to tightly pack the memory needed into one big block, then I would store each node’s index into the memory block and use that to retrieve the relevant instance data for a node during traversal. During tree evaluation, I would pass in the agent’s node instance data for the specific tree and then each node would index into the memory and pull its state data as required. As it turned out, I didn’t need a lot of data per node, I think my heaviest node was around 16bytes, with the vast majority weighing in at around 4bytes. Now this in itself is nothing special but only having a single instance of the tree which all agent were evaluation gave me an idea.
Now it is also worth mentioning that the approach I took with designing the BT was quite animation inspired and so I made use of child trees quite extensively. A child tree is simply a behavior tree that is injected into another tree at runtime. All of our tree were statically allocated so by injected, I simply mean that we would store a pointer to the child tree in a “child tree connector” BT node. During evaluation, we would retrieve that pointer from each agent’s node instance data and trigger an evaluation of that child tree with the agent’s node instance data for the child tree. We would not actually dynamically compose trees in any way, all BTs had a fixed memory size. The child tree concept also allowed us the ability to have multiple agents running different child trees from within the same parent tree connector node. I relied heavily on this mechanism to inject contextual behaviors originating from the environment.
Coming back to the synchronized trees, I will, once again, use a contrived example to discuss the concept. You will notice the use of heavyweight behaviors like “RangedCombat” in the example tree, these are simply examples and I don’t recommend using that level of granularity in your BTs. Anyways, so given the very basic combat tree below, we immediately realize that we will encounter some problems when multiple agents run this tree. Can anyone see what they are?

When we have multiple agents running the tree, they will all throw a grenade if they can and will taunt the enemy if they can. Imagine a battle with 50 enemies, you probably don’t want 50 grenades in the air and 50 taunts at the same time. Design would immediately want to limit the number of agents that can run these behaviors and maybe add some cool downs. A potential quick fix would be to use the blackboard/knowledge. You would give the node an ID, then keep track of how many agents are using it via a counter in the blackboard. The same approach can be used for the cool-down values. I’ve seen other even more convulated appraoches based on specific knowledge flags or even using external systems as synchronization points. Then comes the matter of thread safety and other concurrency issues which is a whole other discussion. In any case, the main problem I find with a lot of these fixes is one of visibility and accessibility, some of them lock out designers from the equation while others make the code fragile since when reordering the tree, the blackboard flags may not be correctly set/unset. In fact, since I believe that the tree should be used to author behavior with a very high granularity, I also believe the tree should be used to solve exactly those problems. So like, I said having a single tree gave me an idea: “what’s stopping us from having a global tree state and using the tree as a synchronization object?” Taking that idea a bit further, we end up with the following tree:

We can use what I termed “Gate Nodes” to help with these problems of synchronization. I was inspired by the talk given by the Yager guys at the Vienna AI game conference, and I borrowed the name from them. I’m not sure that their nodes operate in the same manner as mine but I really liked the idea and the name. The basic premise is that with these “gate nodes” you can globally lock down portions of the tree. The gate nodes have global state which is stored in the tree as well as potentially having agent specific state. They contain a semaphore which allows us to safely control access to sub-branches in the tree. This means that I can now have “Allow Only X agents” nodes in the tree which means that I can limit behaviors globally to only a certain number of agents. As each agent evaluates a gate node, they will try to take a lock on the node, if they succeed they will enter that branch. For example, if I only want to have a single grenade being thrown at any time or only have 3 guys shooting at me while the rest of the enemies charge me then it is relatively easy to do now. And best of all, this can be done without having to touch any agent knowledge or build any external machinery and its clearly visible in the behavior tree.
Furthermore the global state can be used for things like global cool-downs, giving us the flexibility to easily distinguish between local agent cool-down (i.e. special abilities) and global cool-downs (i.e. combat gameplay control by limiting how often grenades are thrown). Best of all, since we only ever have a single instance of each BT, these global locks will also work for all child trees, no matter when and where they are injected, since all child trees are also shared.
I was also playing around with one last use case of the synchronization ability of these trees which i found to be quite elegant. I was using the global tree state to actually coordinate group behaviors. Let’s take a look at the following example:

By using global tree state for synchronization, we can restrict certain behavior branches to only execute when we have exactly 2 agents. We can then assign roles to the agents (for clarity’s sake I’ve left out the conditions for the role assignments). The agents can then perform the first part of their behaviors and once each agent completes they will enter a waiting loop after which we can synchronize their state again. After which they can perform their follow up behaviors. We also have the option to reset the tree for both agent’s if one agent breaks out of the behavior for any reason (i.e. due to an environmental interruption) but I will leave the how as an exercise to the readers in an effort to wrap up this document.
NOTE: One thing that’s necessary to mention is that the above behavior tree would be extremely difficult to construct without using the SSBT evaluation model. In fact, it would be such a pain that that I wouldn’t even recommend trying it.
I personally feel that having global tree states is an incredible tool to have when building behaviors. Unfortunately, I have met a lot of opposition to the idea. In fact, when the BT was evaluated by someone else, the very first thing they did was remove the child tree feature and the global tree state. I don’t know, maybe I’m just an idiot and am missing something? I still believe it to be a good idea and this is in part why I feel that I should write this post. If you disagree or spot some obvious problems, please let me know.
Conclusion
Now in discussing this article with several people, it seems that there is a bit of misunderstanding about what I’m trying to say. I’ve come to the opinion that fundamentally there are two ways to look at behaviors trees:
-
As a tree of behaviors, where the tree represents the decision making structure (i.e. a decision tree)
- As a tree that describes a specific behavior i.e. the set of steps need to perform said behavior.
Personally I think of BTs in terms of 2, this is where they really shine! I think of a behavior as a visual scripting language and I think its a very elegant productivity solution to use BTs as such and this is context for the material I covered in this article. As for using BTs as a tool for defining a characters overall behavior, I feel that BTs are a sub-optimal solution to the problem and I would never recommend them for that. This is exactly what the topic of my next article will be about. What are the problems associated with trying to build a full character behavior with just a BT, and why using BTs is potentially a bad idea.
THANKS: Big thanks to Mika Vehkala for his follow up on this post and our nice long Skype discussion which highlighted some potentially ambiguous portions of the article.


