Recently, I’ve been asked this question several times: “why do you have such a problem with unity builds”. I figured that the question pops up so much that it’s worth writing up. Now I’m not the only person with this opinion and there is an excellent post from 2009, covering most of the problems with unity builds: http://engineering-game-dev.com/2009/12/15/the-evils-of-unity-builds/
What I do want to touch on is the mistaken perception that unity builds actually improve builds times and thereby increase productivity. At first glance you would see a large improvement to build times when doing a full build or a rebuild. And that is true, they do improve full build times. The problem is that I as a programmer don’t do full builds that often. I tend to do a full build only whenever I get a newer version of a code base and even then, that’s often just an incremental build based on the delta between my version of the code base and the latest version. I very rarely ever need to actually do a “rebuild” or full build of a code base as part of my day to day work.
What I actually do on a regular basis is: edit some code, compile, test it and repeat. That is the core workflow of most programmers independent of their industry. That is the workflow that we need to be optimizing and unfortunately unity builds are a huge de-optimization of that. Now why do I say that? Well let’s look a simple example, we have a project with 50 code files and as part of our task we needed to change 2 of those files. In a non-unity build we would change those files then recompile just those 2 code files and we are done. This is illustrated below where the red blocks are the recompiled code files.
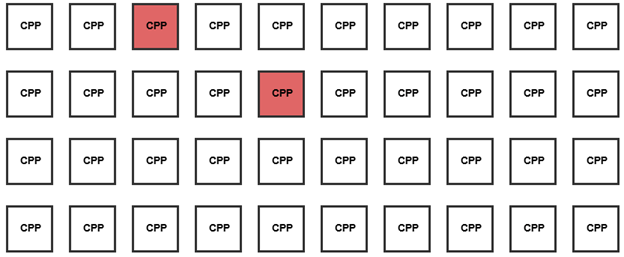
In a unity build scenario, we are required to not only rebuild the code files we changed but also the code files that are unified with the changed files. This is illustrated below where we have taken a very conservative approach to unifying the code files by only grouping 10 files together in a unit.

As you can see for the two changed files we now have to compile the two full units which include all the code from the included code files as well as a lot of headers and templates. This is not efficient especially in the cases where the code you are editing is relatively decoupled from the rest of the project as unity builds will break those de-couplings. And the above scenario is very optimistic since in reality, to see the huge “benefits” of unity builds you would need to unify much larger numbers of files into the units. In previous experience, we had 100+ files lumped together into units. This meant each time I edited a file I recompiled the code for 99+ other files. THIS IS NOT FAST! In fact this is the exact opposite of fast, it is extremely frustrating and a massive waste of a programming time.
An Aside: Unity builds also tend to break a specific workflow of mine that improves my productivity. They prevent the individual compilation of code files. I tend to compile each file individually once I’ve made enough changes to them that I am happy and feel that I’ve reached the end of that iteration. The individual compile helps me to verify that my “includes” are correct as well as any template invocations I might have in the code. I do this via the ctrl-F7 shortcut in Visual Studio. So basically I tend to work on a file and then compile it once I am done, then I move onto editing the next file. I do this so often that it has become a nervous tick for me alongside my almost OCD level of hitting ctrl-s without noticing. The end result of this specific workflow is that I end up manually distributing the compilation of a given change over the course of my edition time. This means when I’m finally done with my changes to the project, I often don’t need to recompile much as I have already compiled everything (unless of course I’ve changed a header). This workflow is really nice since for a lot of day to day changes I don’t change public interfaces that much. Unity builds completely break that for me. Since now the code files are just references that go into a unit once you build the actual project, you can’t compile them individually anymore and in the cases where a build engineer has developed a workaround for that to work, the compiled objects aren’t used for the final build so it’s just extra useless work.
The unnecessary recompilation is a known problem with unity builds and one that even the unity build proponents will admit to. They do have a “solution” that “solves” the issue. Their solution extracts the edited file out of the unit once you edit it into a “working” unit. This means that subsequent edits to those files will only require a rebuild of the work unit. This does improve the situation slightly but it comes with its own set of problems. The first one being that it only helps the cost of the subsequent edits. Imagine that I don’t know in advance all the files that I need to edit, each time I edit a new file, I will have to recompile not only the work unit but also the original unit that contained the file.

So yes, while this does offer an improvement to iteration times over the previous approach, we still have to pay a significant cost each time we edit a new file. And I don’t know about you but I often don’t know in advance exactly which files I will have to edit and so I end up paying these costs. I will say that this approach does have one additional benefit over the previous unity build approach in that in moving the files into a smaller work unit you can validate that you are not missing any includes that might have gone unnoticed in the larger unit (note: this only kinda works since potentially the order of the cpp includes in the work unit might once again hide an inclusion issue).
This brings us to the second problem which is that the code you are compiling locally is not the same as what the build machine is compiling and this can result in frustrating issues since you will be generating a different set of compiled objects than the build machine. Obviously, you can then create a mechanism that once the code is tested, you can locally generate the same units as the build machine and then test that but this means practically a recompile of the project since potentially a lot of units will be affected and it obviously adds a completely unnecessary extra compile and testing phase (and cost) t to your development. And god forbid you find an issue that exists when merging the units, cause then you might as well join the circus with all the experience of jumping through hoops you’ll be getting.
So these are the relatively obvious issues with unity builds, so how about we cover a less obvious issue, one that is a real iteration killer: header files. Imagine the project setup highlighted below, we have a set of header files that are included by several code files across two projects. This is a pretty standard setup.
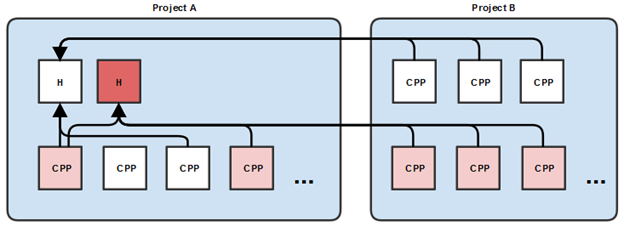
In a normal setup, if we change a header file in project A, then we will need to recompile the dependent code files in project A and in project B. So the change of the one header only results in the recompilation of 5 files. Now imagine the unity build scenario, we don’t really have control over how we group our code files into the units so we may end up with the following setup:

Now instead of having to recompile only the five files that depend on that header, we have a massive amount of work to do. And this problem only grows the lower down the header is in your project hierarchy. Even if you were extremely careful with your include patterns and limited the inclusion of a header to only the bare minimum number of files needed, it doesn’t matter unity builds will throw away all your hard work. In fact, you might as well not care about your inclusion patterns since that header will get included in a ton of places. In fact, in previous experience, in changing a lower level header, I ended up literally recompiling more than half of the entire codebase, this is simply insane. I almost see unity builds as a tool for lazy programmers that don’t want to have to think about their code architectures and include patterns. As far as I know there is no “solution” to the above problem. I can imagine trying to build up a database of all the code files in the code base, have a list of their include files, then do some sort of topological sort (assuming no cyclic dependencies between headers exist – LOL) to try to group the code files in units that minimize the unnecessary includes and so on. Realistically though, that’s not really feasible because to get the low granularity of code files needed for an effective unity build, you will have to have a massive amount of redundant includes.
I was previously working on a project where I had created two new projects (one dependent on the other) for my systems, I avoided using unity builds for them and enjoyed a good iteration time especially compared to my colleagues that were working in the rest of the codebase. Then an over-zealous build engineer moved my projects over to unity builds and I went from 5~10sec build times for a change to 45s-1m per change since now I pretty much ended up rebuilding the dependent project every time I changed a header in the base project.
When complaining about this, the build engineer just looked at me and said that yes it’s true that my iteration times are much worse now, but look at how much faster the projects compile on the build machine. I had no idea how to (politely) respond to that. From my point of view, the production costs in terms of hamstringing your entire development team’s iteration times greatly outweigh the cost of a slightly slower build on a build server.
And this is one of the biggest problem I’ve experienced in terms of dealing with the proponents of unity builds. Simply that they tend to only look at the rebuild times for the whole solution and completely forget that people actually work in that solution and don’t constantly rebuild it. Yes, unity builds really help the overall build time but they also really fuck up iteration times (not to mention that they actually break language features i.e. translation unit locals and anon namespaces). And I really hope that people will stop and think about what the cost in terms of productivity is, before blindly moving over to some sort of unity build system.

I’ve been at studios that do builds wrong, but my current studio does it pretty well.
We are pretty careful to not include too many files in our conglomerates. Usually this is a once a year cleanup task to break big conglomerates into smaller ones. We can keep a clean build to a few minutes for a really large codebase.
We can also switch between unity builds and conventional builds very easily, so can get the best of both worlds. This is super important because everyone locally builds code – including artists and designers for whom iteration is not as important as build times.
Wouldn’t it also be possible to delegate the local builds for content people to the build machines and have a mechanism whereby a content provider can simply retrieve a build for version X?
In terms of having the two compile targets: there are a lot of issues that I’ve seen where code will compile in one build target (unity) but not in another. For example, I had local constants in my code files that clashed when they were unified and I had to add ugly namespaces to avoid the clashes. In general, I’m not a fan of things that break core language features.
I would also argue that for any codebase where unity builds makes a huge difference, there are other non-unity techniques that can result in similar results without all the problems and the hit to iteration times.
It’s interesting to hear you talk about this. Ubisoft Massive recently rolled out a unity build that fixes a lot of these problems and I had thought that it was something we had borrowed from Ubisoft Montreal.
In our build system we start with a single project unity file containing a rather large number of cpp files. When a cpp file is first edited the build system then removes that file from the unity file and builds it as a standalone file. The result is that you pay the cost for recompiling the unity file again when you edit a new file, but subsequent incremental changes to that file only require a single file rebuilt.
With this in place my only problem with unity builds is now that they make anonymous namespaces in cpp files worthless for preventing symbol name collision within a project.
Hi Phil, that’s exactly the scenario I described straight after the “An Aside” section. You are still paying a large cost each time you edit a new file and it doesn’t solve the header issue, so no I don’t think the only issues is the anon-namespaces.
As I mentioned to Justin, there are significant improvements that can be made to a codebase that can have similar results as unity builds without all the extra headaches.
As for the specific system you mentioned, I know exactly what you are talking about but I don’t think it’s worth me commenting about that on a public space. If you want poke me on skype and we can discuss it further.
The biggest problem we’ve found with unity builds is submitting code that works in unity because of inherited dependencies, but requires fixing missing includes for conventional builds. We solve by having build server report on the conventional variation of the build (in the same way we build non-lead platforms and debug, release, final etc. ), and since that happens in a timely fashion and we require folk to keep all builds clean, the rare conventional failure doesn’t linger long. We also never really see problems with multiply defined symbols across translation units. The setup simply hasn’t been a problem for us, and since we can iterate quickly and clean build quickly, there’s been no motivation to change. Now YMMV of course, but the common case for us is that it works perfectly most of the time 🙂
Do you guys have any metrics on whether unity builds actually helped at all in terms of programmer workflow. In my experience, they’ve always been slower for incremental builds especially for localized changes.
The multiple defined symbols happened to me cause I built a node based system and had a constant node serialization ID in each node file. Once unified I had to namespace all those IDs. Really ugly, also bit me in the ass several times with cpp locals as I tend to extract all magic numbers into a anon namespace block at the start of the cpp.